本文翻译自Calculus on Computational Graphs: Backpropagation,文章句子表述有变化,但尽量保持了内容一致。
简介(Introduction)
反向传播算法是训练深度网络模型的关键算法,它和梯度下降算法一起使用时,相较于原始的方法,可以使神经网络的训练速度快上千万倍以上。直观的对比是对于一个模型训练的时间消耗,用与不用的差别可能是一周与二十200,000年。
反向传播算法不仅仅被用于深度学习,在其他领域里它也是一个有力的工具,从天气预测到数值稳定性分析都离不开它——区别在不同领域中有不同的名字。事实上,这个算法在不同领域里至少被改进过十多次了(参见Griewank (2010))。总的来说,不考虑其应用场景的话,一般被叫做“反向模式微分”。
从根本上来讲,它只是一种快速求微分的方法,但却是在深度学习以及其他的数值计算领域中,必不可少的一项技术。
计算图(Computational Graphs)
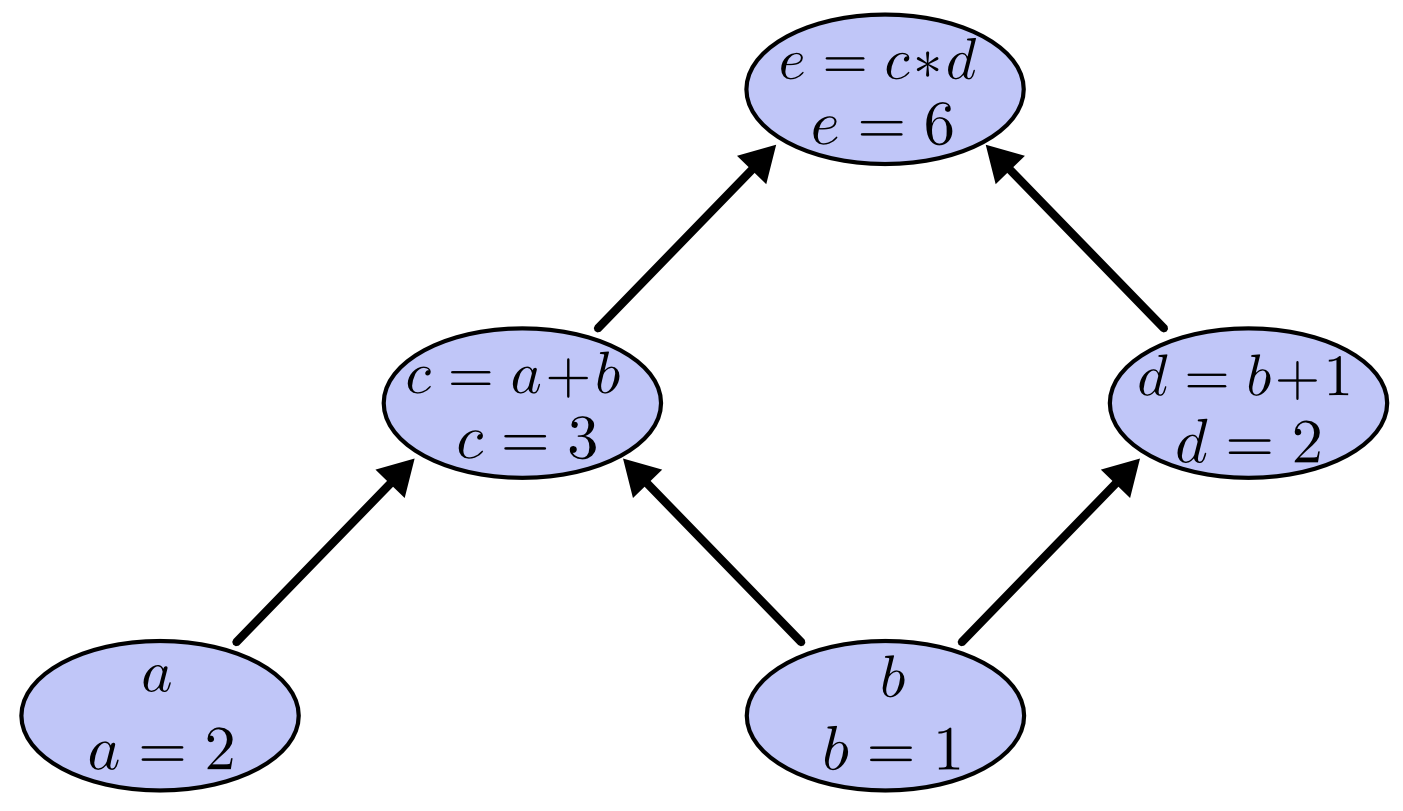
计算图是一种有效的用于考察数学表达式的方法。举个例子,在表达式 e = (a+b)*(b+1) 中,一共有2个加法、1个乘法。我们定义两个中间变量 c和 d,将计算流程改造如下:
|
|
将上面的三个操作转化为节点,每个节点接受操作的输入。节点间的箭头从上一操作节点指向下一操作节点,从而构建一个计算图:

这种图在计算机科学中很常见,特别是在函数式编程中,比较类似于依赖关系图或者是调用图。这种图更是著名的深度学习框架Theano的核心抽象内容。
通过对图的输入赋值,我们可以通过一层一层的向上计算得到图的输出,例如设定输入 a=2,b=1,则得到输出为e=6。
计算图上的微分(Derivatives on Computational Graphs)
如果你想了解计算图上是如何微分的,那么你需要从图中的箭头开始探究。比如a可以影响c的值,那么它是如何影响的呢?我们可以通过给a一个很小的变化来观察c的变化。这就是我们所谓的偏导数的由来。
为了计算这个图,我们需要先准备两个求导法则:加法法则和乘法法则,在这里应用这两个法则有:
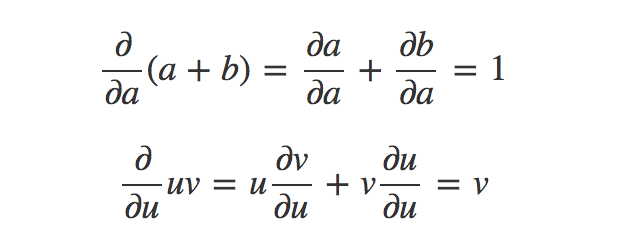
这样在图的每个箭头上都有了一个偏导数标签:
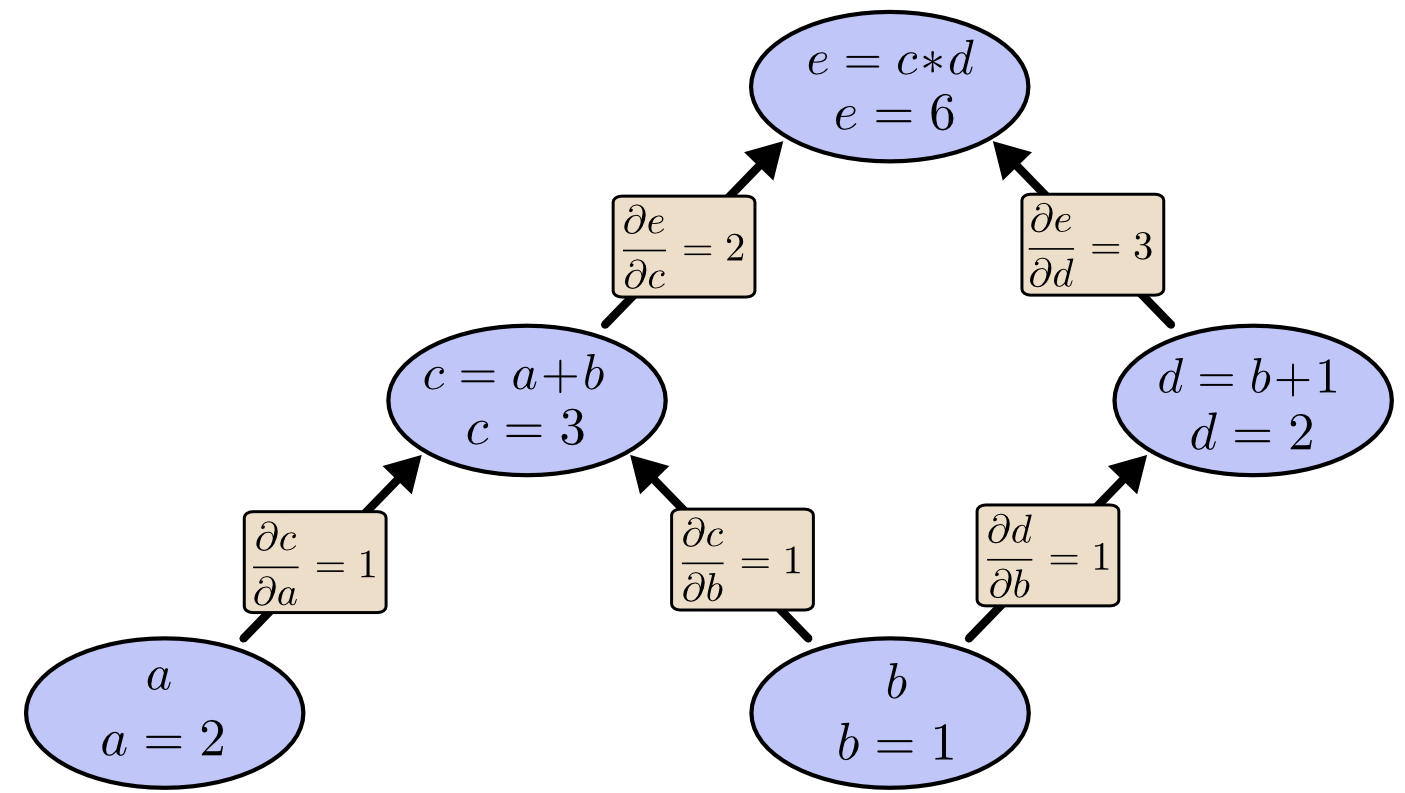
那么问题来了,那些不直接连接的节点是如何互相影响的呢?我们考察e与a的关系,假设上图中a以加1的速度增长,那么c会随着也以加1的速度增长,而e会随着c的增长而以加2的速度增长。从而可以得到e会随着a的变化以2倍的速度随之变化,即e关于a的偏导数为2。(假设b=1不变)
从图中观察这个规律是将起点与终点之间的所有路径遍历,每条路径中箭头上的偏导相乘,再将每个路径的值相加。这样来计算e对于b的偏导数有:
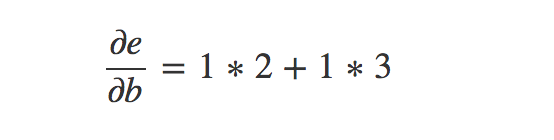
这就是b如何通过c与d来影响e的,这种将所有路径的结果相加的方法就是我们在求导中使用的多变量链式求导方法的另一种展现。
权值路径(Factoring Paths)
上面的方法很简单,但是很容易导致路径规模爆炸。一个简单的例子,下图X到Y有三条路径,Y到Z又有三条路径,那么X到Z一共有九条路径。
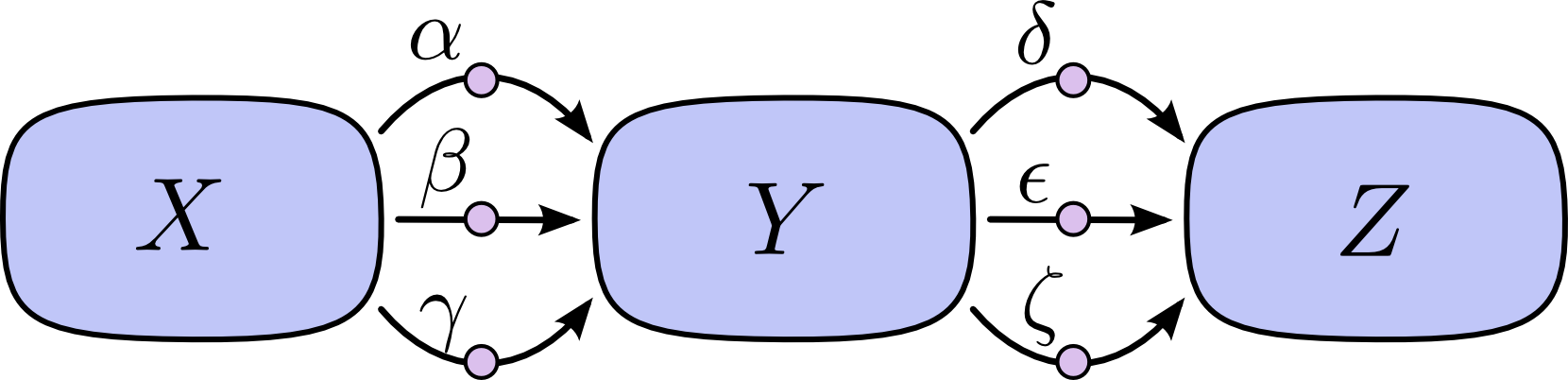
那么在求偏导数时,就会有如下的形式。但是当整个图变得复杂的时候,这个加法的式子会越来越复杂。路径的个数会随着复杂度以几何级数形式增长。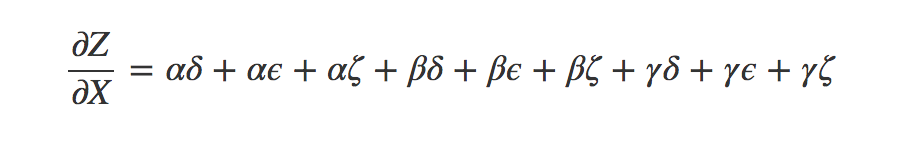
不妨换一种表达方法,这样看起来比上面好多了。
从上式的思想中我们可以引入前向微分和反向微分的概念了,它们都是计算路径权值和的高效算法。这两个算法不是简单地将路径值相加,而是通过合并节点的方法来高效计算总和,事实上,这两个算法只会对每个箭头处理一次。(简单的路径相加会多次计算同一个箭头)
前向微分就是从输入开始,沿着图的方向计算直到结束。在途经的每个节点,将该节点的所有输入相加,这样就获得了该节点对所有输入变化的反馈,即微分值。然后继续向后移动,重复上述方法,最终计算出最终结果。
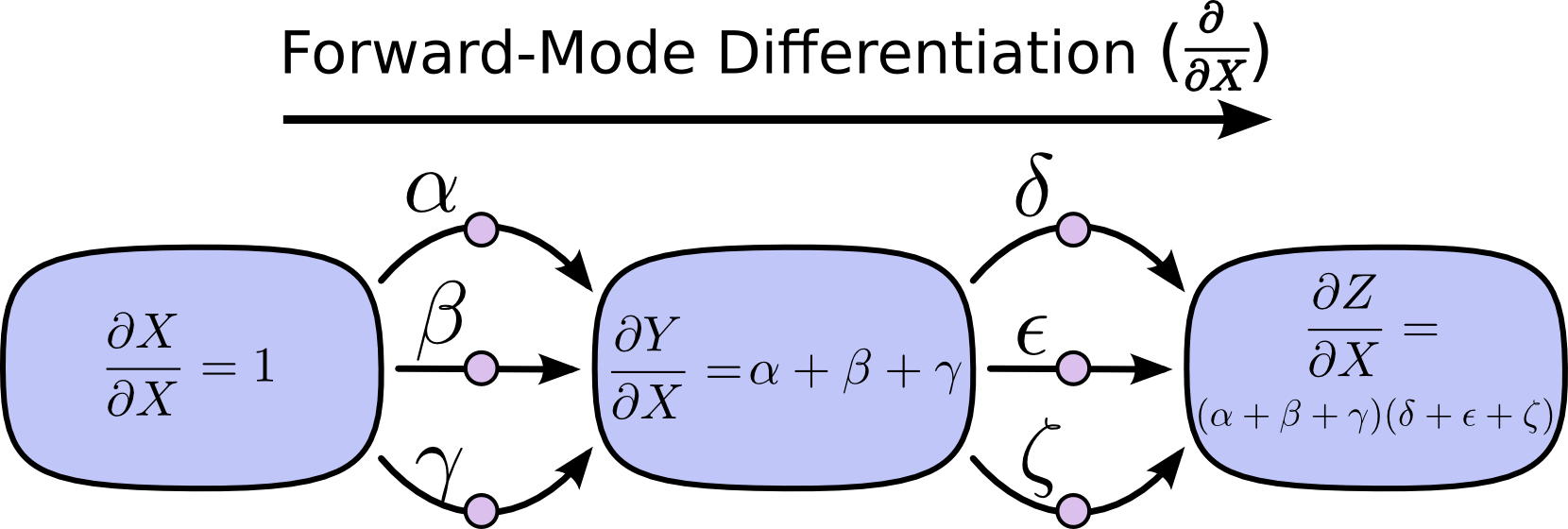
反向微分则是从输出节点开始,逆着图的方向反着计算每个节点对最终输出的影响,即该节点对最终输出的偏导值。

简单的说这两种方法,其实就是:前者是对每个节点计算 d/dx,而后者则是对每个节点计算dz/d
快捷计算(Computational Victories)
说到这里,你估计还在觉得这两种算法如此相似,为什么大家更关心反向微分呢?和前向微分相比它的计算方法很别扭,难道它有特别的优势吗?
让我们再来考虑文章最开始提出的例子:

我们使用前向微分来计算e对于b的偏微分值,由此我们需要计算出图中所有节点对b的偏微分值,当计算到达顶点时,可以获得一个偏微分结果,即de/db = 5:
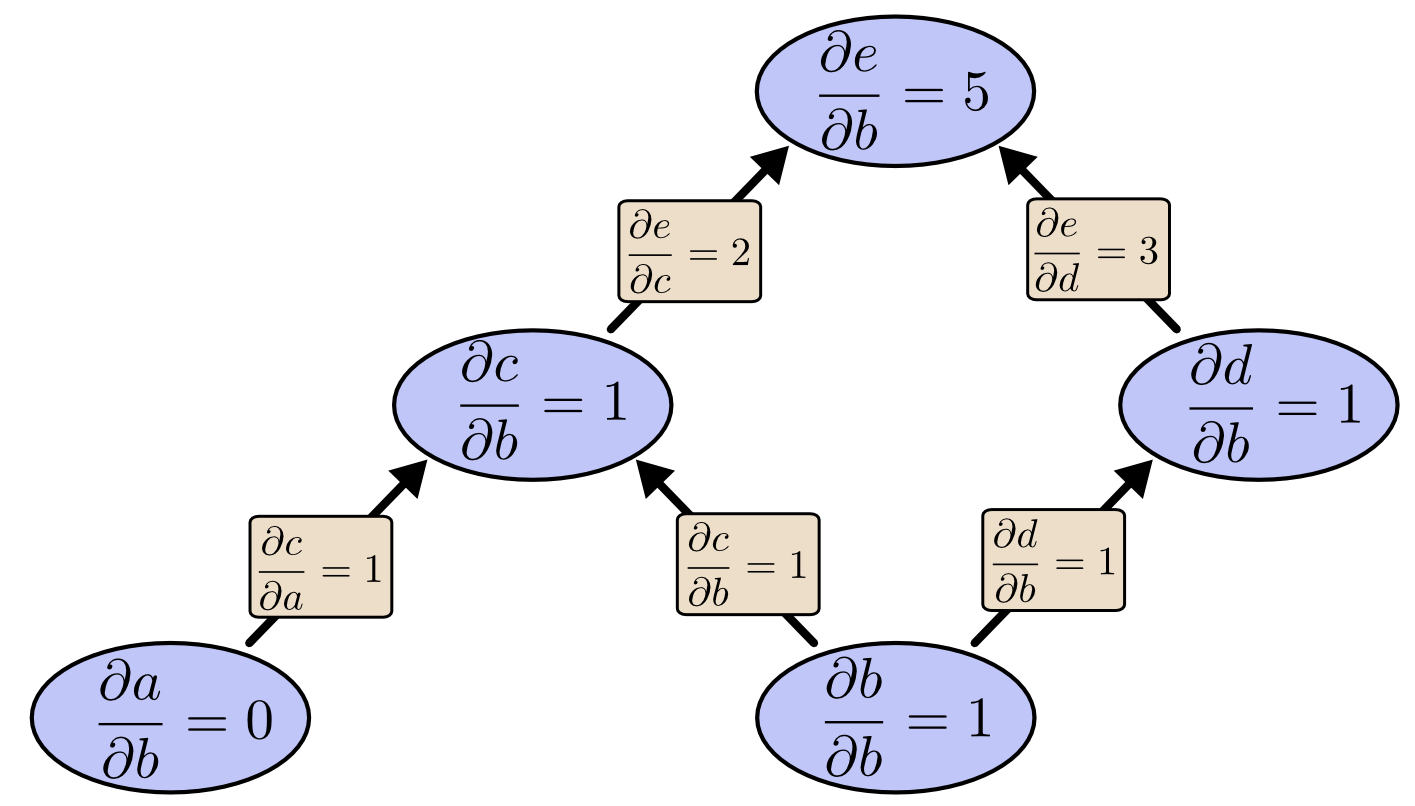
但我们来使用反向微分来计算同样的任务时,我们会计算出e对于图中所有节点的偏微分值,但计算到达底端时,我们获得了两个偏微分结果,即de/da=2与de/db=5:
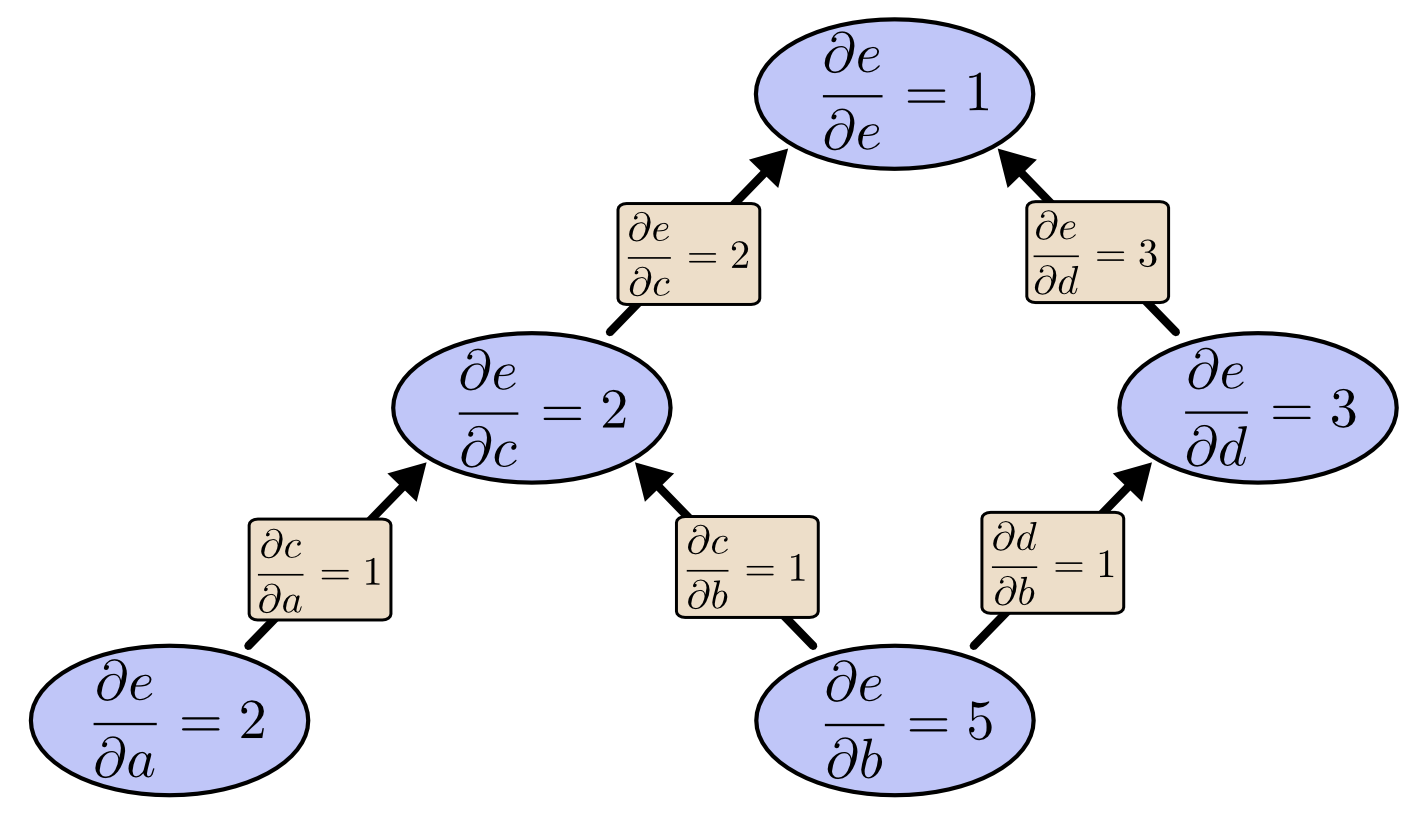
看到没有,这个差别十分明显,前向微分一次只能计算输出关于一个输入参数的偏导数,而反向微分则可以计算出关于所有输入的偏导数,而且还有中间节点的偏导数(即中间节点对输出的影响)。
这个图中只有两个参数,因此可能影响不大,但是假设有一百万个输入和一个输出的系统中,前向微分需要我们通过数一百万次重复计算来获得偏导数,而反向微分则只需一次!一百万的加速是相当不错的!
而针对神经网络,我们一般会在输出时计算损失函数来评价网络的好坏,来针对网络中的许许多多参数进行优化,这正好是符合很多输入,一个输出的模型,使用反向微分可以直接一次计算出所有参数对输出的影响(梯度),从而将整个系统的计算速度大大提升。
说到这里,当然我们也可以得出一个结论:前向微分也有好用的时候,即当系统是一个输入,很多输出的时候。我想这个应该不难理解。
这个算法很难吗吗?(Isn’t This Trivial?)
当我第一次搞明白反向传播算法时,我的第一感觉是“这不就是链式求导法则吗?没什么不得了的 啊,为什么他们花了那么久才搞出来这个算法?”事实上,我不是唯一这么想的人。如果你只是问:“有没有一种快速计算前馈神经网络中,参数的偏导数的方法?”,那么针对这个问题来找到这个算法作为答案确实很简单。(作者的意思是,如果你知道了你需要用偏导数来更新网络,你的目标明确了,那么你很容易找到这个算法。)
但是,在反向传播算法被发明时,首先前馈神经网络本身就不被关注(译者注:当时神经网络受制于硬件条件,性能很差),而且由于没有反向微分算法,所以偏导数计算消耗很大,通过偏导数(梯度)来训练网络也不是主流思想,导致更加没有人研究反向传播算法,这是一个循环的困境。所以说哪怕是以今天的视角来看,这个算法在当时发明也是很厉害的。
所以说这就是个事后诸葛亮的问题,一旦你知道了采用这种方法会有好的结果,那么其实就等于你找到了这种方法。事实是,在你不知道这个方法会有效,甚至并不知道这种方法存在时,你怎么去找到这个方法呢?这才是最难最牛逼的的部分。
结论(Conclusion)
下面就不翻译了,主要内容上面都讲完了。
Derivatives are cheaper than you think. That’s the main lesson to take away from this post. In fact, they’re unintuitively cheap, and us silly humans have had to repeatedly rediscover this fact. That’s an important thing to understand in deep learning. It’s also a really useful thing to know in other fields, and only more so if it isn’t common knowledge.
Are there other lessons? I think there are.
Backpropagation is also a useful lens for understanding how derivatives flow through a model. This can be extremely helpful in reasoning about why some models are difficult to optimize. The classic example of this is the problem of vanishing gradients in recurrent neural networks.
Finally, I claim there is a broad algorithmic lesson to take away from these techniques. Backpropagation and forward-mode differentiation use a powerful pair of tricks (linearization and dynamic programming) to compute derivatives more efficiently than one might think possible. If you really understand these techniques, you can use them to efficiently calculate several other interesting expressions involving derivatives. We’ll explore this in a later blog post.
This post gives a very abstract treatment of backpropagation. I strongly recommend reading Michael Nielsen’s chapter on it for an excellent discussion, more concretely focused on neural networks.
致谢(Acknowledgments)
Thank you to Greg Corrado, Jon Shlens, Samy Bengio and Anelia Angelova for taking the time to proofread this post.
Thanks also to Dario Amodei, Michael Nielsen and Yoshua Bengio for discussion of approaches to explaining backpropagation. Also thanks to all those who tolerated me practicing explaining backpropagation in talks and seminar series!